O2O 电商高可用架构实践
近年来 O2O 电商从群雄逐鹿到一家独大(美团),可谓是发展迅速,高可用的电商系统架构也成为高级开发工程师的工作内容和挑战。本文介绍电商系统的架构设计,在微服务的指导思想下,电商系统改如何从全局到局面设计各个系统,以及每个系统中需要着重考虑的问题。
说明:关于本文中 O2O 电商的定义,由于笔者工作的互联网公司是最简单的团券网站,所以本文中只考虑简单的团购网站,而不考虑像美团外卖这样的外卖系统。
O2O 电商 整体介绍
1.1 盈利模式
O2O 的盈利模式大致有:
- 团购、酒旅服务费、抽成;
- 入驻费;
- 区域加盟商费用;
- 广告流量费,类似淘宝的竞价排名 外卖市场外包给地区承包商;
- 其他增值服务,定向推广等;
- 先收钱后付钱的现金流带来的金融收益。
其中抽成是指,销售和商家谈好业务,商家入住平台,给平台一个优惠的价格(成本价),设置一个原价(市场价),和售卖给用户的价格(团购价)。平台给一定的补贴,最后以优惠价售卖给用户。毛利就是优惠价-成本价。
那 O2O 电商的模式就是:销售谈商家->商家入住->商家上单->C 端检索展现->用户浏览->使用优惠(可选)->下单->支付->给用户发放券码-用户到店消费验券->订单核销->对账->给商家打款。除了核心流程,也有其他分支流程比如:用户浏览->查看评论->电话预约->查看地图->消费完评论、收藏等。在这个过程中,风控也是比不可少的部分,主要是为了打击黄牛党、羊毛党。
从上面的流程中,我们大致可以知道电商系统分为用户、商品、订单、营销、评论、风控等几大块。下面我们先整体介绍系统架构图,然后挑几个核心的模块进行详细介绍。
1.2 电商系统整体架构
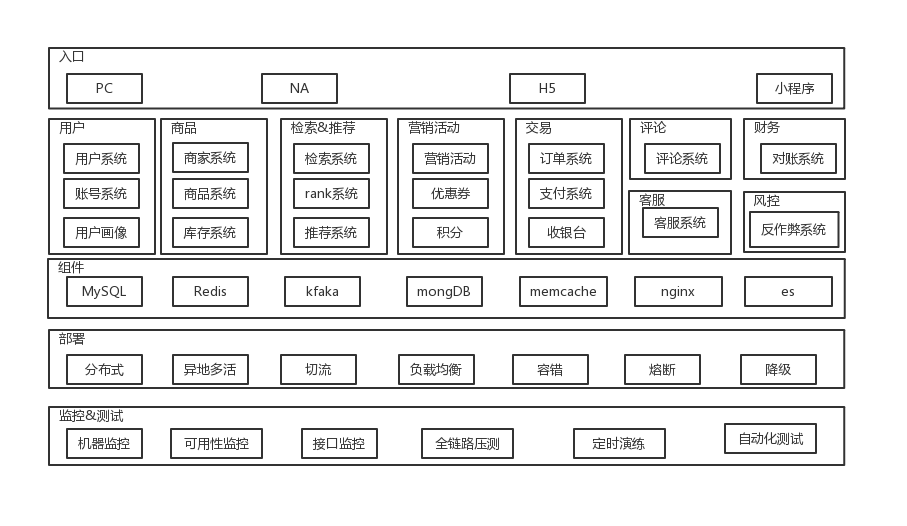
图1 电商系统整体架构图
首先是入口层,现在一个电商系统会有很多个端,比如说 PC、NA、H5 和小程序。然后我们往下看,一般会发划分为用户系统、商品系统、检索和推荐系统、营销系统、交易系统,以及其他一些小系统,比如说评论、客服,财务、风控等;再接着往下看,是这些系统使用的一些通用组件,比如 MySQL、Redis、 Kafka、MongoDB、memcache、Nginx、ES 等。然后呢这些服务往往都是分布式部署。一般还会考虑到异地多活,以及运维的自动切流和负载均衡、系统的容灾熔断、降级等。
为了保证系统的稳定性,在监控和测试方面还会做机器级别的监控、系统可用性的监控、接口的监控,以及从测试的角度会做全链路的压测、定时演练和自动化测试。其中第二层是本文的重点 ,各个子系统都是一个独立的微服务,各个微服务之间协作共同提供给用户服务。下面我先说一下订单产生的过程,对系统有个深入的了解
1.3 订单的产生过程
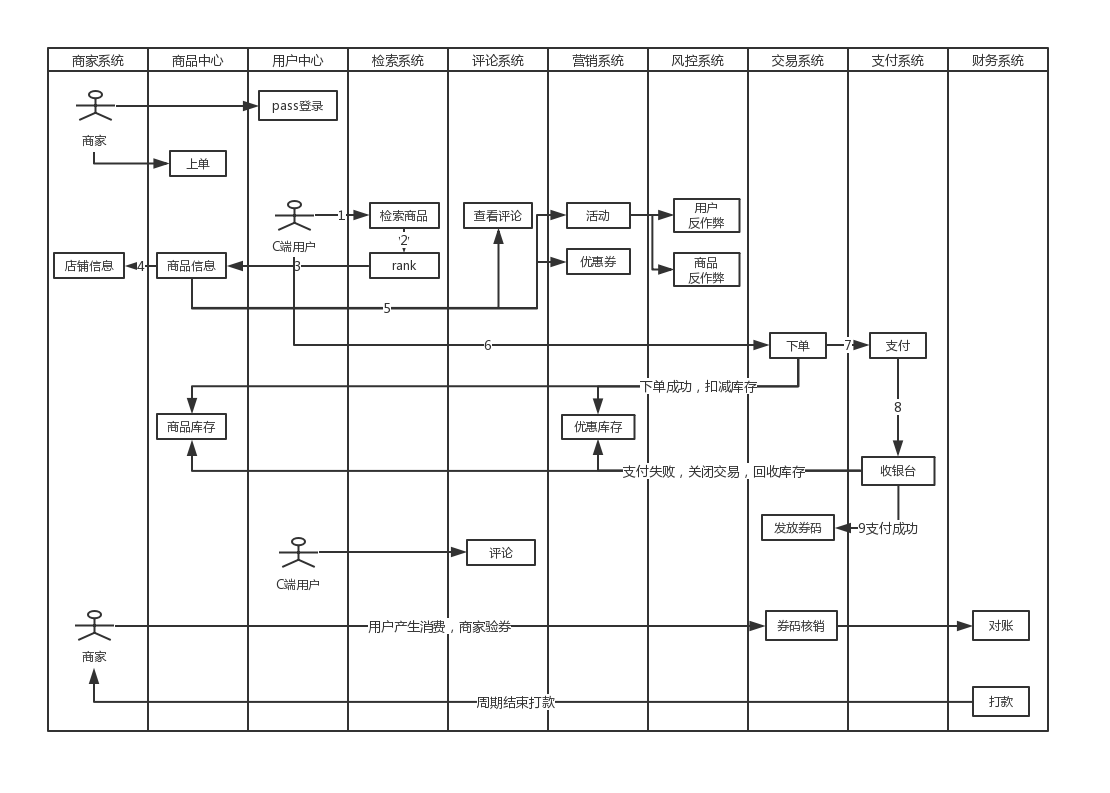
图2 一个订单产生的过程
我们从左往右开始看:首先是商家,商家通过用户中心的 passport 登录到系统以后,先开店,提供营业执照等,等待审核。运营人员审核通过后正式开店,商家可以操作上单,就是把自己的商品录入到平台上,基本信息包括商品名称、价格、照片,当然也可以设置商家优惠等。
然后是 C 端用户通过 passport 登录到系统,C 端用户通过两种方式触达商品:
- “猜你喜欢”类型推荐出来的商品;
- 进行商品检索,检索系统会经过排序,给出相关性较好的商品。
用户去请求这个商品的详细信息,以及用户可能会附加查看他的店铺信息、评论、优惠活动等(活动和优惠券都要经过反作弊系统,主要包括用户反作弊和商品反作弊)。如果用户觉着满意会下单,就会走到下单流程来。下单成功会扣减商品库存,如果使用了优惠活动,也会扣减优惠库存。下单完成进行支付,支付会调起收银台,现在的收银台一般会支持微信和支付宝、还有自有的支付系统。如果订单支付成功,就会给用户发券码,如果订单支付不成功会提示订单在支付中,提示用户再次支付。如果关闭交订单,并把扣减的库存给释放掉。
用户购买完团购券之后,会去商家那里进行消费。消费完之后可以进行评论。商家把用户的券码进行核销,核销的情况会同步到财务系统。商家等到一定周期以后,平台就会和商家结算进行打款。
以上是 O2O 电商的核心流程。下面我针对几个核心微服务进行详细的介绍。
用户服务
以下一些场景会依赖用户服务:
- 用户注册登录、找回账号密码;
- 用户个人信息修改;
- 内部系统用户信息查询,比如营销活动查询该用户是否新客,判断是否能够参加新客活动,一般是拿 userid 进行查询的;
- 客服系统,通过手机号、邮箱等查询用户的基本信息,登录日志等;
- 数据需求,查询某个时间段内、某些区域注册的用户量;
- 反作弊,按照 IP 聚合注册的账号;
- 推荐系统对用户的画像等,这个有的公司可能不放在用户系统中,可根据实际情况考虑。
总结下来用户系统主要包括两大功能,面向 C 端用户的注册登录和面向内部各个系统的多维度的、多筛选条件的用户信息查询。
下面是用户系统的架构图。
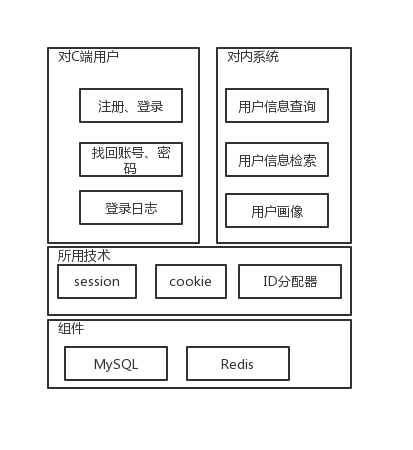
图3 用户系统架构图
2.1 注册登录
注册登录也就是 passport 系统,目前常见的登录方式:
- 手机号+验证码
- 手机号+密码
- 用户名+密码
- 邮箱+密码
- 第三方登录,QQ、微信、微博
- 人脸、声音等
常见的注册方式:
- 手机号+验证码+密码
- 邮箱+验证吗+密码
- 第三方登录之后再绑定手机号
2.1.1 登录系统的第一阶段
电商网站的初级阶段,往往只有一个系统,在这一个系统登录即可,技术上就使用 session 和 cookie 就可以了,用户通过浏览器访问网站,未登录态需要填写用户名和密码,完成登录认证。这时,我们在这个用户的 session 中标记登录状态为 yes(已登录),同时在浏览器中写入 Cookie,这个 Cookie 是这个用户的唯一标识。下次用户发请求时会带上这个 Cookie,服务端会根据这个 Cookie 找到对应的 session,通过 session 来判断这个用户是否登录。Cookie 存放的内容就是 sessionID,它的值在服务端是唯一的。
如果再加上 QQ、微信、微博等第三方登录,以微信登录为例,可以参考微信的账号接入官方文档–移动应用微信登录开发指南,通过文档可以看出微信登录的第三方授权是基于 OAuth2.0 协议标准构建的。
2.1.2 登录系统的第二阶段
随着业务的不断发展,可能衍生了很多个子系统,比如阿里巴巴有淘宝、天猫、支付宝等。如果每个系统都独立登录,用户估计会疯掉的。那就需要本公司的系统,只需要在一个平台上登录,其他的平台能够自动登录,这也是我们常说的单点登录问题。
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO 的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。(来自百度百科)
单点登录的解决方案有三种。
2.1.2.1 子域解决单点登录
在弄明白这个问题之前,先说明一下 Cookie 与 domain 的相关概念:
- 主域名和二级域名,比如 baidu.com 是百度域,tieba.baidu.com 是百度的子域。
- 主域名之间 Cookie 是不能共享的,比如 baidu.com 和 taobao.com 的 Cookie 肯定是不能共享的。
- 二级域名能读取设置了domain 为顶级域名或者自身的 Cookie ,不能读取其他二级域名 domain 的 Cookie 。比如 tieba.baidu.com 与map.baidu.com 之间的 Cookie 不能共享,但是 tieba.baidu.com 能够读取到 baidu.com 的 Cookie。
- 二级域名能够写主域名和自身域名,而不能写其他的二级域名。
比如我们有个域名叫做:baidu.com,同时有两个业务系统分别为:tieba.baidu.com 和 map.baidu.com。我们要做单点登录,需要一个登录系统,叫做:sso.baidu.com。sso 登录以后将 Cookie 的域设置为顶域,即 .baidu.com,这样所有子域的系统都可以访问到顶域的 Cookie。子域 map.baidu.com 拿到 Cookie(sessionID) 带到了 map.baidu.com 的服务端,怎么通过 Cookie 拿到 Session 呢,通过共享 Session 就可以解决了。
总结来说,就是子域 Cookie 设置顶级域名,加上共享 Session 解决单点登录问题。
2.1.2.2 CAS 解决单点登录
同域下的单点登录是巧用了 Cookie 顶域的特性。如果是不同域呢?比如 nuomi.com , 就不是 baidu.com 的子域名, CAS 流程是解决单点登录的标准流程。
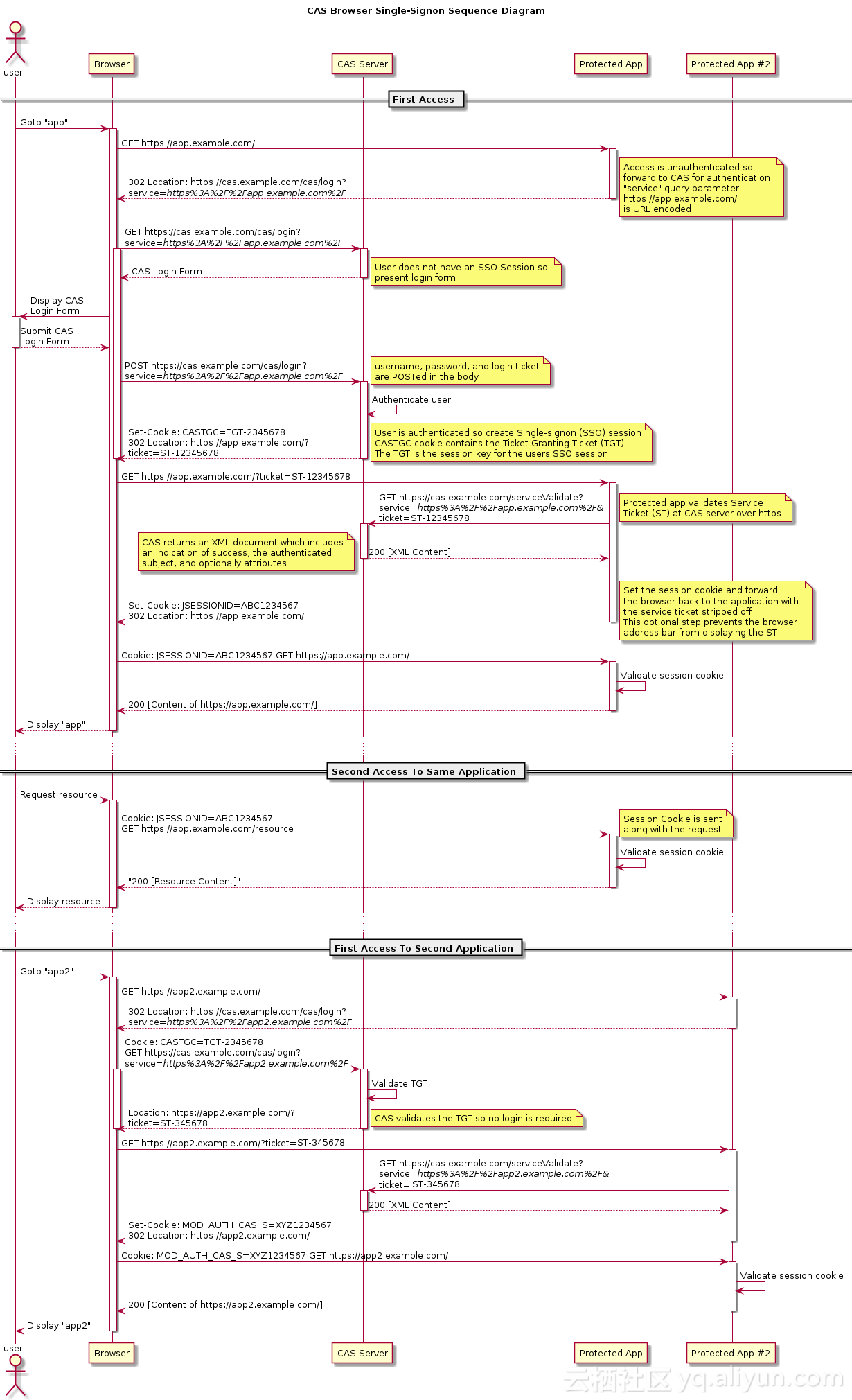
图3 CAS 原理图 引用自CAS官网
具体流程如下:
- 用户访问 app 系统,app 系统是需要登录的,但用户现在没有登录。
- 跳转到 CAS server,以后图中的 CAS Server 我们统一叫做 SSO 系统。SSO 系统也没有登录,弹出用户登录页。
- 用户填写用户名、密码,SSO 系统进行认证后,将登录状态写入 SSO 的 session,浏览器中写入 SSO 域下的 Cookie。
- SSO 系统登录完成后会生成一个 ST(Service Ticket),然后跳转到 app 系统,同时将 ST 作为参数传递给 app 系统。
- app 系统拿到 ST 后,从后台向 SSO 发送请求,验证 ST 是否有效。
- 验证通过后,app 系统将登录状态写入 session 并设置 app 域下的 Cookie。
至此,跨域单点登录就完成了。以后我们再访问 app 系统时,app 就是登录的。
接下来,我们再看看访问 app2 系统时的流程:
- 用户访问 app2 系统,app2 系统没有登录,跳转到 SSO。
- 由于 SSO 已经登录了,不需要重新登录认证。
- SSO 生成 ST,浏览器跳转到 app2 系统,并将 ST 作为参数传递给 app2。
- app2 拿到 ST,后台访问 SSO,验证 ST 是否有效。
- 验证成功后,app2 将登录状态写入 session,并在 app2 域下写入 Cookie。
这样,app2 系统不需要走登录流程,就已经是登录了。SSO,app1和 app2 在不同的域,它们之间的 session 不共享也是没问题的。
说明:本节内容参考了阿里云的文章
2.1.2.3 OAuth2.0 解决单点登录
像上面的微信登录一下,我们把各个子系统理解成第三方系统接口即可。 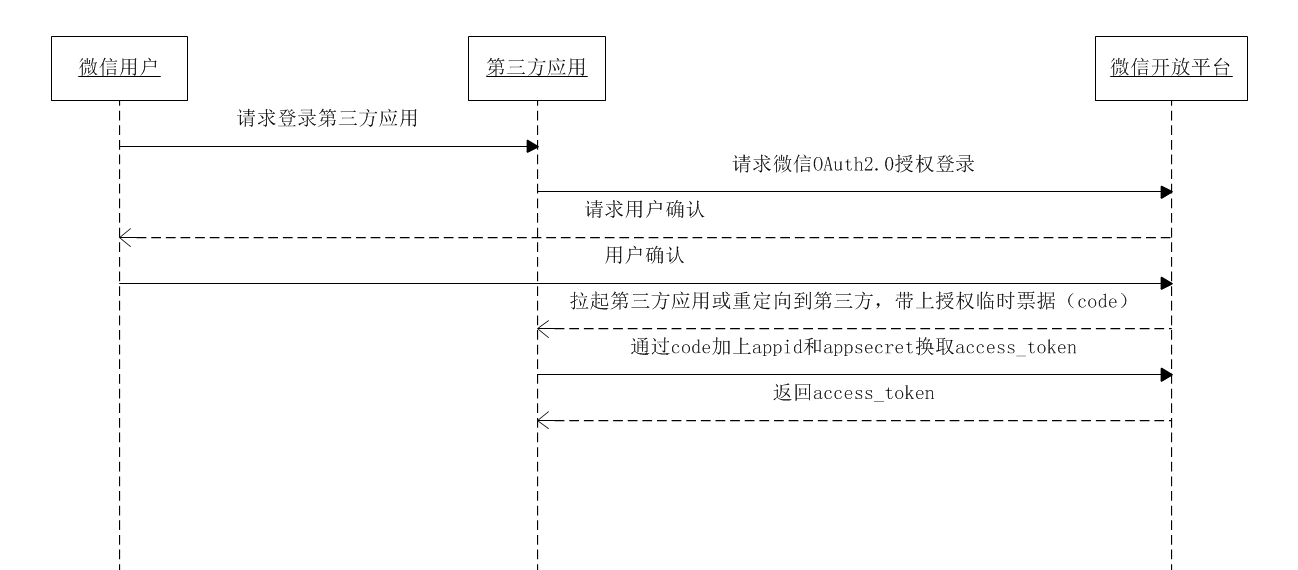
图4 微信OAuth2.0 接入流程引用自移动应用微信登录开发指南
OAuth2的流程是:
- 用户访问点击微信请求登录 app 系统。
- app 跳转到微信登录页,带上参数 appid 和回调地址(backUrl)。appid 是第三方系统在微信上注册的账号,微信开放平台根据 appid 查找到 app 的注册信息,校验参数 backUrl 和注册的回调地址是否一致如果校验不通过则返回错误,校验成功则返回授权页。
- 微信弹出授权页,用户确认,用户授权后, 微信开放平台(OAuth Server)会生成这个用户对应的 code,并通过 app 的 backUrl 返回 app 系统。
- app 系统拿到 code 后,再带上 appid 和 appSecret 从后台访问微信开发平台(OAuth Server),换取用户的 token。
- 有了 token 就能获取用户的授权信息了,并把 cookie 设置为登录态
说明:本节内容参考了阿里云的文章
2.1.3 登录系统的第三阶段
随着公司的不断壮大,用户量不断累积,达到了微博、微信的级别,这时候就有别的小网站想要通过第三方登录的方式登录他的网站了,这时你就需要提供通用的账号接入能力,用到的技术就是 OAuth2.0 ,和上面的微信接入是一样的道理。内部系统接入是一样的,当成第三方应用,接入即可。所以等业务发展到一定的阶段,使用 OAuth2.0 即可,避免以后还需要升级。
2.2 用户信息存储
从根本上来说,用户服务包括后面的商品服务、交易服务都是存储系统,我总结下来,存储系统分成 4 个部分:支撑在线服务的存储、离线数据存储、ES、订阅。有了这 4 个部分,几乎能够满足所有的场景需求。
2.2.1 在线存储的数据库设计
2.2.1.1 UID 的设计
UID 作为用户信息的唯一标志,在数据库中是数据库的主键。另外方便查询等,UID 的生成基本是趋势时间递增的。UID 的生成一般有以下几种方法。
取当前毫秒数
<?php $uniqId = hexdec(uniqid());
优点:
- 本地生成 ID,不需要进行远程调用,时延低;
- 生成的 ID 趋势递增;
- 生成的 ID 是整数,建立索引后查询效率高。
缺点:
- 如果并发量超过 1000,会生成重复的 ID。
注意:写 QPS 不能大于 1000。一般情况下,用户注册的 QPS 也不会到 1000。
snowflake 算法
snowflake 是 twitter 开源的分布式 ID 生成算法,其核心思想是:一个 long 型的 ID,使用其中 41bit 作为毫秒数,10bit 作为机器编号,12bit 作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成 $1000_(2^{12}),也就是,也就是,也就是 4_10^6$ 个 ID,完全能满足业务的需求。
- 1 位,不用。二进制中最高位为 1 的都是负数,但是我们生成的 id 一般都使用整数,所以这个最高位固定是 0;
- 41 位,用来记录时间戳(毫秒)41 位。可以表示 241−1241−12^{41}-1 个数字,转化成单位年则是 69 年;
- 10 位,用来记录工作机器 id。可以部署在 210=1024210=10242^{10}=1024 个节点;
- 12 位,序列号,用来记录同毫秒内产生的不同 id。可以表示的最大正整数是 212−1=4095212−1=40952^{12}-1=4095,即可以用 0、1、2、3…40940、1、2、3…40940、1、2、3 … 4094 这 4095 个数字,来表示同一机器同一毫秒内产生的 4095 个 ID 序号。
注意:这个位数的分配不是一成不变的,可以根据自己的并发量,调整 bit 位的分配。
hash 摘要算法
这种情况适用于根据不同的字符串计算出唯一的 ID,作为一个字符串唯一的标志。我上次遇到的情况是根据一段文本,存储这段文本的特征,因此每段文本需要生产不同的 ID。
代码示例
<?php
$content = "hello world";
$ret=creat_sign_fs64($content);
$id = sprintf("%u", ($ret[1] << 32) | $ret[0]);
或者
<?php
$content = "hello world";
$u = unpack('N2', sha1($content, true));
$id = sprintf('%u', ($u[1] << 32) | $u[2] );
hash 摘要算法,可能会出现碰撞,最好压测一下。
2.2.1.2 用户系统表结构
表的设计要满足登录功能和用户信息查询功能。登录需要根据手机号、用户名、邮箱登录,因此手机号、用户名、邮箱是唯一索引;用户信息会使用 UID 进行查询,因此 UID 也是唯一索引。
因此登录表和用户详情表是分开的,同时登录表要考虑到第三方登陆的扩展性。
登录表 user_auth 设计包括 user_id、phone、email、username、weixin_uid、weixin_token、weibo_uid、weibo_token、password
使用手机号登录的时候,查询语句是
select user_id from user_auth where phone='phone' and password='password'
或者第三方登录时,
select user_id from user_auth where weixin_uid='uid' and weixin_token='token'
如果使用微信登录,后续绑定账号,可以把信息更新进去,比如绑定手机号,就把 phone 加进去。
用户信息详情 user_info 表字段包括 user_id、name、sex、address 、create_ip、level 等等其他用户属性信息。
如果用户在千万级别,使用上面两个表,完全没有问题。可如果表扩张到几亿用户,就需要考虑分库分表。用户信息详情表使用 user_id 进行分表。登录表使用 user_id 进行分表就不合适了,因为没办法进行查询。可以考虑使用 nosql 的存储组件代替 MySQL,表结构也进行相应的调整。
2.2.2 离线存储的设计
电商中经常根据用户的行为,来挖掘用户画像。用户画像又能用于反作弊和推荐。用户画像信息有的就存放在离线存储上,常见的有 Hadoop+hive,查询就使用 hive 或者 spark。
2.2.3 ES的设计
有些客服查询需求,他的查询条件不是 UID,而是在某某时间段注册、手机号大概是什么等等查询条件进行筛选。就需要用 ES 中查询用户信息。
2.2.4 订阅的设计
有的需求是用户信息发生变更,会触发另外一些操作,比如用户等级升级,会给用户发消息提醒,这些需求,可以订阅用户服务的变更,做自己的业务逻辑,因此,用户服务也会提供订阅模块,把响应的消息发送给订阅的需求方。
2.3 用户服务小结
这一部分总结了用户服务提供的能力和实现方式,给电商系统加上了一个良好的基石。
商品服务
3.1 基础概念
在零售领域,商品存在 SKU 和 SPU 两个概念。SKU=Stock Keeping Unit(库存量单位),即库存进出计量的单位,可以是以件,盒,托盘等为单位。SKU 这是对于大型连锁超市 DC(配送中心)物流管理的一个必要的方法。当下已经被我们引申为产品统一编号的简称,每种产品均对应有唯一的 SKU 号。 针对电商而言,SKU 有另外的注解:
- SKU 是指一款商品,每款都有出现一个 SKU,便于电商品牌识别商品;
- 一款商品多色,则是有多个 SKU。例:一件衣服,有红色、白色、蓝色,则 SKU 编码也不相同,如相同则会出现混淆,发错货。
SPU(Standard Product Unit):标准化产品单元。是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。通俗点讲,属性值、特性相同的商品就可以称为一个 SPU。引用自百度百科
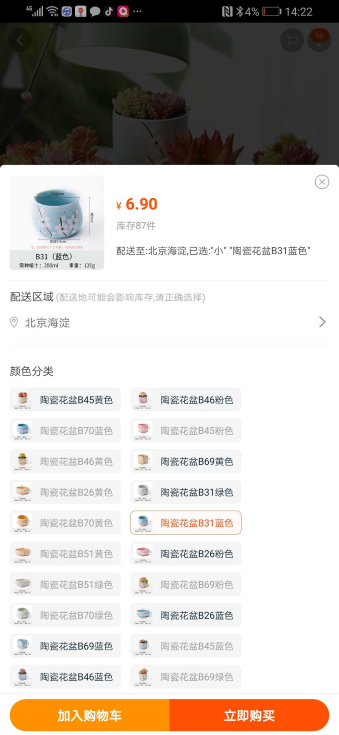
如图中,多肉花盆就是一个 SPU,它下面有多个类型颜色,价格也不同,是一个 SKU,可以理解成 SPU 是一些 SKU 的集合。
O2O 电商中的团券,可以没有 SKU 的概念,电商中都是 XX 元团 XX 元券,相当于一个 SPU 只有一个 SKU,那 SKU 的概念就可以忽略。
商品系统的设计很重要,关系到订单系统、营销系统怎么设计,订单和营销都是发生在商品上的行为,要记录商品 ID。我主要说一下没有 SKU 概念的商品设计。
3.2 O2O 商品服务系统
商品服务系统也是存储系统,存储系统就是增删改查。查询的场景有商家查询商家下面所有的商品信息,根据商品 ID 批量查询商品信息,用户 query 检索,客服检索等。增加商品的地方有,上单系统。上单系统和下单减库存会修改商品信息。
商品的基本信息有商品 ID、商品名、描述、一级分类、二级分类、团购价、成本价、库存、图片、类型等。
商家查询的顺序是商家 ID -> 商品 ids -> 商品信息。
客服查询的话,通过 ES 查询,和上面的用户服务是一样的。
修改信息是根据商品 ID 修改库存。
像团购体量是几百万商家,几千万个商品,就不需要分表了。
3.3 SPU、SKU 商品服务系统
在表设计时,可以是按照 SPU 设计,SKU 是个 json。另外一种设计方式是 SKU 表也按照单行设计,从属哪个 SPU,保存的记录中。
营销系统
营销系统是电商类网站很核心的系统,期望给公司拉新、带来流水等。整个营销系统也是有很多个微服务构成的。如下图,营销整个系统包括广告位配置、组件化活动页、摇一摇等运营活动、促销引擎、优惠券等。着重介绍一个促销引擎和优惠券系统。
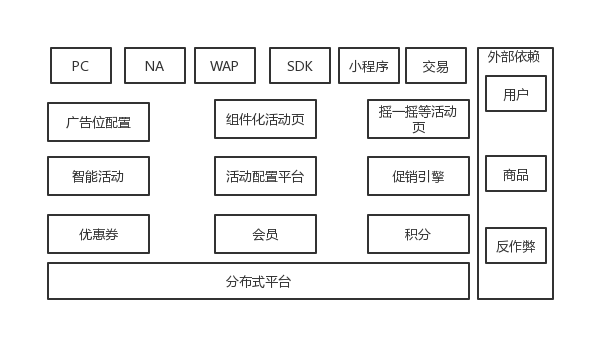
图5 营销系统架构
4.1 促销引擎
说明:团购电商中的促销系统和淘宝等的区别是没有购物车,都是单商品进行支付的。因此没有讨论组合促销和购物车促销。
4.1.1 促销系统定义
促销的定义是:在某段时间满足某种条件的用户在某些商品上根据某些规则参加促销活动,希望带来拉新、流水增长的行为。
4.1.1.1 营销活动类型
营销活动类型包括以下场景的几种方式,
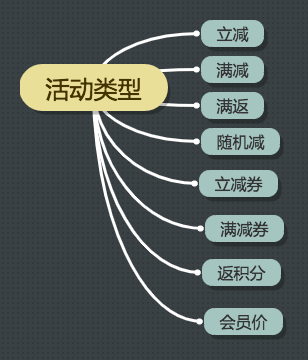
图6 营销活动类型
另外根据补贴补贴来源方一般分为平台活动和商家活动。
4.1.1.2 常见的促销引擎规则
营销活动肯定有响应的规则,符合某些条件的用户才能参加活动,下图是场景的活动规则。 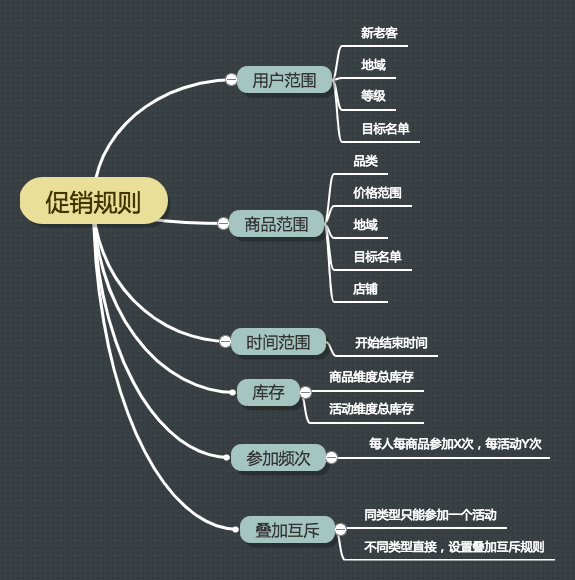
图7 营销活动规则
4.1.2 促销系统基础功能
促销系统是在用户浏览商品时告诉用户商品有什么活动;在用户下单时 check 活动是否还能够参加,并扣减活动的库存;在支付的时候再次 check 活动是否能够参加,并记录活动信息。
就比如你去逛街,每个衣服上都会写着能参加什么活动,减多少钱。等你说你要买了,店家去看看你还能参加这个活动不,(可能因为优惠份数卖完了或者活动结束了等等你不能用活动了)。如果能,店家就把这个衣服预留给你了(别人想买的时候,只能告诉别人,以后被你占用了)。等你完成支付,店家会做下记录,谁买了哪件衣服用了哪个优惠活动。如果你一直不支付,店员只好告诉你这个衣服只能给你留一个小时,要不就卖给别人了,这就是库存释放的问题了。
另外有运营人员进行活动的配置,因此促销的功能大致可以通过下图进行表示。活动运营人员配置活动,用户浏览、使用活动下单、使用活动支付、支付后续的操作等。
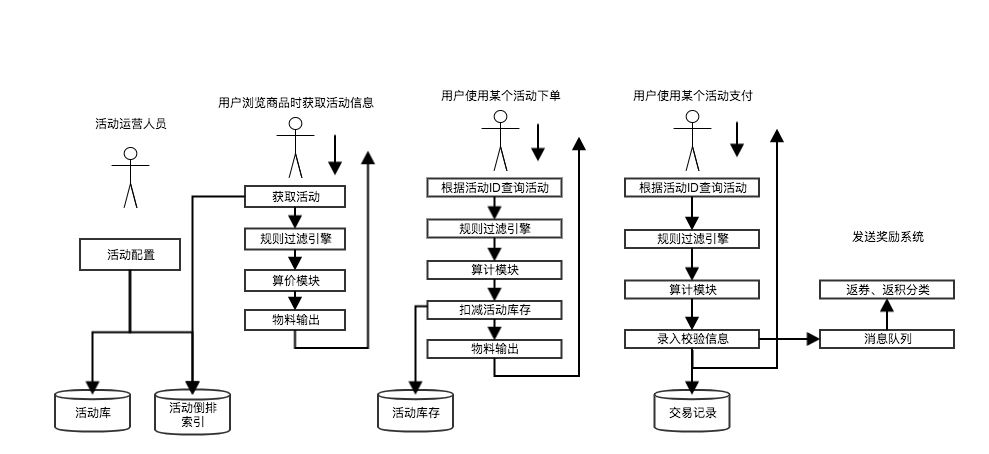
图8 促销系统基础功能
4.1.3 促销系统的设计
促销系统的接口有三类:
- 提供查询商品优惠活动的接口,可支持单商品或者批量。这个接口是读接口,不会写任何数据;
- 下单时再次 check 优惠活动,并且减优惠库存,这个接口有写的部分,只要是扣减库存;
- 支付时再次 check 活动,并记录下订单使用某个活动的接口,这里也有写的操作,还记下用户消费过的活动和次数。用来再次请求活动的时候check用户是否还能参加。还有如果是发奖品的活动的话,异步发奖。
其中第一类接口的通用流程是促销系统拿到商品配置的优惠活动,根据各种规则过滤掉不能参加的活动,根据活动规则算计,按照减价最多输出最终能够参加的活动的物料和算价。总结下来就是获取配置的活动->过滤掉不能参加的活动->计算每个活动的优惠价->输出活动信息。
- 第一步:获取配置的活动
由于一个商品上面可以配置很多个活动,这个是没有限制的,那如何获取能参加的活动呢。运营在配置活动的时候是活动id对用的规则,比如某个分类都能参加,或者白名单商品能参加。往往是 id1->catg1 ,id2->goodId1、goodId2 这样配置的。那获取商品活动怎么办呢,商品 goodId1,先获取商品详情,它的分类是 catg1,那去取活动就是去 catg1 下面的活动以及 goodId1 下面的活动,因此获取活动的时候是根据商品的分类或者商品 Id 或者店铺 Id 等获取的。因此要建议活动规则和活动 id 的倒排索引。
那什么时候创建倒排索引呢,最好的时机是配置活动的时候,通过异步队列创建。活动下线时应该在倒排索引中删除,另外一个问题是活动到期如何处理,毕竟活动到期不会触发事件,如果到期不删除的话,又会增加接口的计算量。一个解决思路是定时脚本跑过期的活动,进行删除。那倒排索引存在什么地方呢,一般可以考虑 redis,第一它是内存存储的,速度快,第二它支持的数据结构多,一个分类下有多个活动,可以用 hash 或者 set 的数据结构。获取活动的时候就会从多个 redis key 中获取,应该用 redis 的 pipe 方式,减少耗时。
第二步:过滤活动
根据促销规则过滤活动,需求提前想好有哪些过滤规则,怎么并行过滤,另外过滤规则的顺序也有考量。
第三步:算价
需要考虑叠加互斥的规则。如果是单一活动就是最简单的场景。能够叠加的情况下也应该考虑活动的优先级,比如立减>满减>满返等。
第四步:物料输出
不同的活动类型也会配置不同的物料,组合算计结果进行输出。
第二类接口:下单时再次 check & 扣减优惠库存。这时 input 是商品 id,订单 id,活动 id,活动优惠金额。output 可以是 yes or no,也可以是活动 id,优惠金额,让促销引擎系统再次判断 check。目的就是询问你之前告诉我,这个商品能参加这个活动能优惠这么多钱,现在还可以吗,可以的话,你帮我把优惠库存锁住。和上面的读接口基本流程是一样的,就第一步不一样,不用获取活动,而是已经直接指定了活动。
这里有两个最常见的问题:
为什么是下单减优惠库存
首先下单减库存还是支付减库存都说我们促销系统决定的,并不是交易系统决定的。如果是支付环节减的话,多个用户抢占最后一个库存的时候,会有用户支付失败,用户体验不好。因此我们使用了下单减库存。下单减库存还有一个问题就是库存释放的问题了。订单的释放可以用异步队列的延迟发送功能,等窗口回来的时候判断是否需要是否库存。如何保证库存不超买 最常见的是给库存加锁,使用 redis 的 incr,因为它是原子操作。
第三类接口,支付完成再次 check 优惠活动,并记录优惠情况,异步发奖等。这时 input 是商品 id,订单 id,活动 id,活动优惠金额。output 可以是yes or no,也可以是活动 id,优惠金额,让订单系统再次判断 check。和 2 类接口不同的是,它真正的达成了交易,需要把交易信息记录下来,方便对账使用,还要扣减优惠次数等。和 2 中的接口流程也差不多。这个接口一定要做的是幂等性。
4.1.4 促销系统的性能指标
低延时:
上游对促销引擎的耗时要求应该是 3 个 9 分位 100ms。可以通过大量使用 redis、并行化、预充 cache 等方案解决。
高可用:
接口稳定性要求是 4 个 9,能够做到异地多活最好。
4.2 优惠券服务
电商系统中,优惠券也是比较常见的营销手段,和促销引擎相互协作。
4.2.1 优惠券系统的需求
优惠券的产品逻辑是,通过给多样化形式给用户发券,这些券都有相应的规则信息,然后引导用户使用优惠券,促进订单的达成,在使用完抵用券之后进行核销,订单异常退款时返还用户的优惠券。另外除了用户层面,公司层面需要知道优惠券的使用情况和效果,财务对账等。下图是我梳理的优惠券的产品形式。
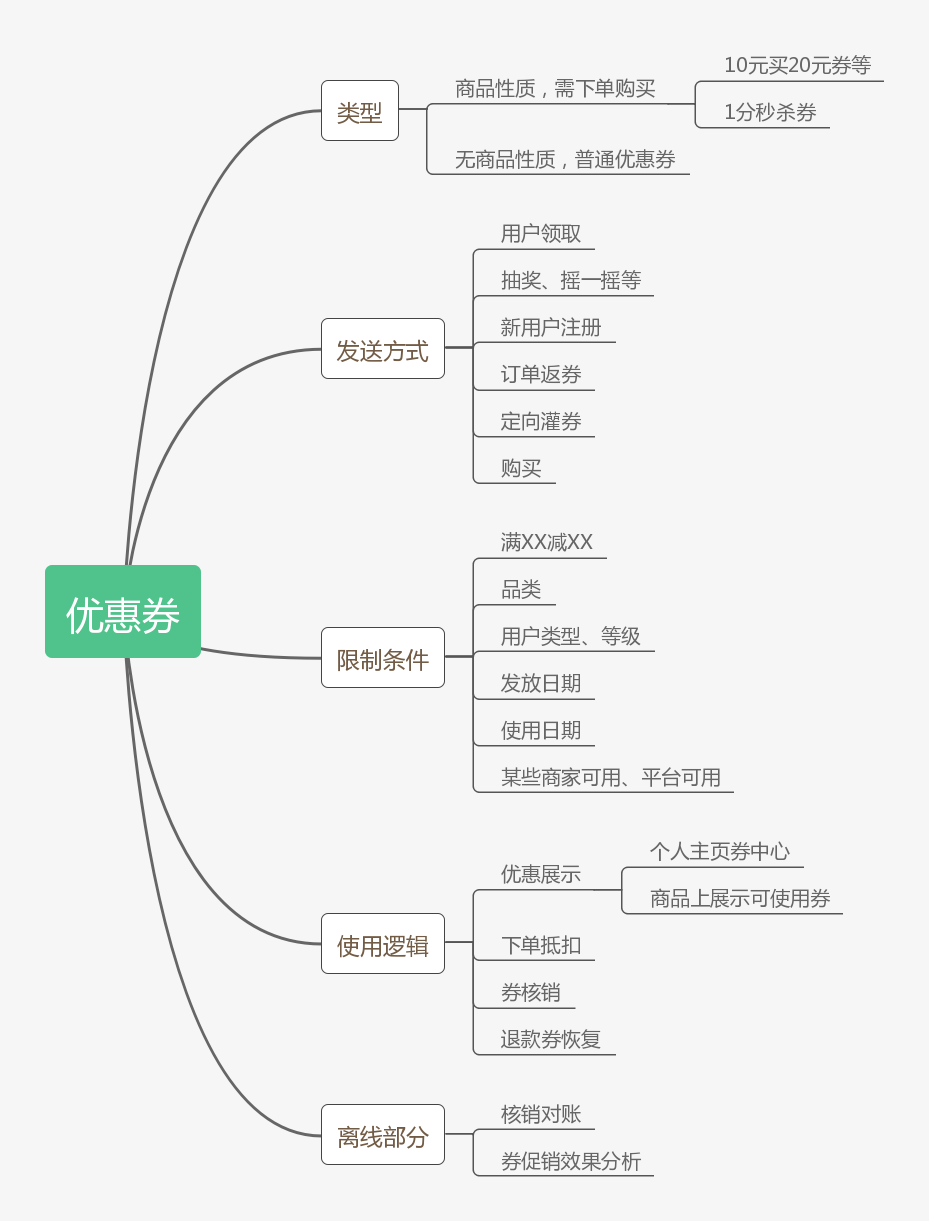
图9 优惠券产品逻辑
4.2.2 优惠券系统的设计思路
先类比一下线下优惠券使用的流程。比如我们去一家火锅店,店里搞了一个活动,给每个客户免费发送一张满 200 减 50 的优惠券。那店家需要做什么呢,先去做一批优惠券,确定好张数,比如一共 100 张。优惠券上标明使用日期等。因此对店家来说就有一个优惠券批次的概念。
在互联网中优惠券系统的用户就有下面几类角色
- 运营人员
- 普通用户
- 老板或者财务
其中运营人员配置优惠券,优惠的券的规则一般和活动的规则类似。普通用户可以领券、展现、使用。老板主要是观察优惠券的使用情况。
从接口设计设计来说,基本包含新增批次、修改批次、下线批次;发券、请求用户的券情况、使用券。
从表设计来说,基本包含批次表、用户券表、券消耗核销记录表。
4.2.3 优惠券系统的架构
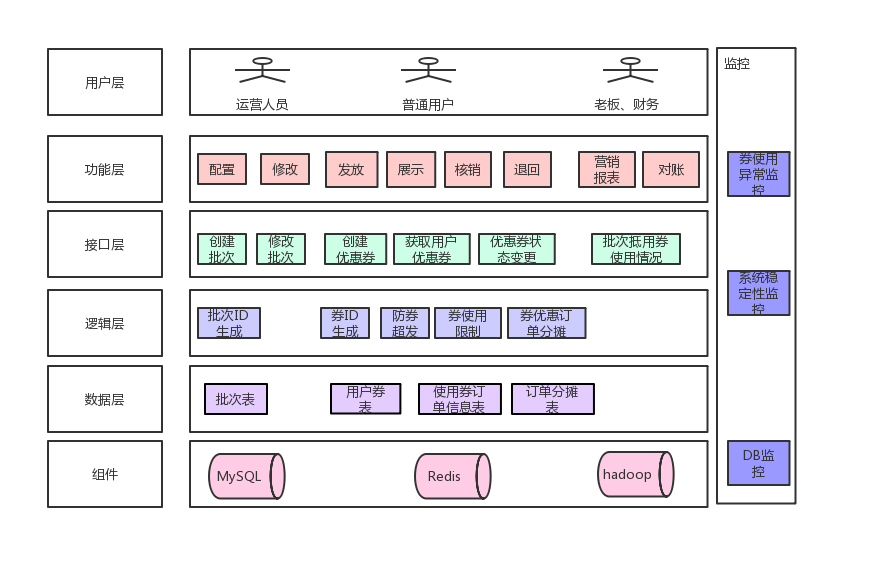
图10 优惠券系统架构
上图是优惠券系统的架构设计,自下而上看首先是存储使用 MySQL,为了对 MySQL 进行保护,缓存使用 Redis,离线数据存储在 Hadoop 集群上。表的话批次表、用户券表、券消耗核销记录表、订单分摊券表。逻辑层有批次 ID 生成、券 ID 生成,防止券超发、券使用限制等。接口层有创建、修改批次,创建优化券、查询优化券等。
4.2.4 优惠券系统的高可用方案
在优惠券系统中,我们往往会遇到下面几个难点:
大量灌券时对 DB 的压力 灌券一般是直接往 SQL 里面灌,这种效率比较高,但是大批量的灌券的话,会给 DB 带来压力,注意控制一次写的频率和使用 SQL 批量操作来降低风险。
券 ID 的设计 可以参见用户章节的 ID 设计
分表问题,是按照用户ID分,还是按照券 ID 分 系统中一个有三个 ID 概念,批次 ID,用户 ID,券 ID。建三张表,批次信息表,用户与券 ID 映射表(使用用户 ID 分表)、券信息详情表(使用券 ID 分表)。查询用户有哪些券,先去 2 中查券 ID,再去 3 中查券详情。直接查券信息的话,直接查 3 即可。
超发问题 Redis incr 计数。
高读问题 使用 Redis 缓存,对 DB 进行保护。
订单服务
在美团的介绍中,美团日订单量有 2000 多万,按照 MySQL 分表,每天的订单量都存满了一张表。订单服务相较于用户服务、商品服务更为复杂。首先量级大,其次是复杂度高,最重要的是和资金相关,安全性、系统可用性的要求也高。
5.1 订单表的设计
订单表的设计,第一、面向三个角色,商家、C 端用户与客服,如何分库分表是个难题。
- 按照 C 端用户 userid 分表,C 端用户查询没有问题,但是商家端如何查询呢?商家端需要用商家 id 查询,那就满足不了需求了。
- 按照商家 id 分表,那 C 端的查询需求就无法满足了。
- 客服的查询都是模糊查询,比如用户投诉的时候,会记不得订单号。只能大致描述一些信息进行筛选。
一种解决方案是冗余存储,C 端产生订单,同步给B端,C 端和 B 端分表按照自己的需求建立索引,就满足了各自的需求,对于客服的需求,将订单数据存放到 ES 中。这种方式,要保证BC端订单数据的最终一致性。
第二,分多少张表能够满足需求呢,按照日订单量有 2000 多万,分 8192 张表,能够支持 20-30 年。
第三,订单包含的信息有:订单基本信息,订单号、订单状态、下单时间、支付时间、退款时间;订单的用户信息,用户 id;订单的商品信息,购买的商品、有效期至、订单的优惠信息、参加的活动 id、优惠情况;订单的支付信息,使用什么渠道支付、会员积分抵扣、活动优惠金额等。
5.2 订单状态的管理
订单的状态有下单完成、待支付、支付完成、退款、已消费、已评论。各个模块的流程控制订单状态的流转。可以抽象出来一个订单状态机,专门管理订单的状态。具体的状态机就不在赘述了。
系统高可用方案
6.1 架构的概念
6.1.1 分布式 CPA 原理
CPA 定律美国著名科学家 Eric Brewer 在 2000 年提出的,其中
Consistency:数据一致性——读操作是否总能读到前一个写操作的结果,即是说在分布式环境中,多个读入口读到的数据是否一致。比如 MySQL 的主从架构,数据同步是同步 blog 同步的,数据在同步的过程中,数据是不一致的。再比如订单系统和商品库存系统的扣减库存操作如果同步失败,就会造成库存不一致,进而发生库存的超卖。数据一致性的概念总是和数据延迟是一起出现的,比如 MySQL 的数据延迟是 ms 级别的,认为它是能够保证实时的,还有不保证实时性的情况,会完成数据的最终一致性。
Partition Tolerance :分区容错性,任何一个分布式计算系统都是由多个节点组成的。在正常情况下,节点与节点之间的通信是正常的。但是在某些情况下,节点之间的通信会 断开,这种断开成为 “Partition”。在分布式计算的实现中,Partition 是很常见的,因为节点不可能永远不出故障,尤其是对于跨物理地区的 海量存储系统而言,而容错性则可以保证如果只是系统中的部分节点不可用,那么相关的操作仍旧能够正常完成。
Availiability:可用性,系统能够能用户提供稳定的服务。
CAP 理论明确指出:在一个分布式计算系统中,“C”、“A”、“P”不能同时成立,最多只能同时成立两条,即在设计分布式计算系统时,一致性、可用性和容错性三者不可兼得。因此,分布式计算系统的设计和实现必须针对用户的实际需求,在上述 3 个原则之间进行权衡。
6.1.2 可用性
可用性的定义是平均修复时间(MTTR)/(平均故障间隔时间(MTBF)+平均修复时间(MTTR))
Availability = MTBF / (MTBF + MTTR)
通常大家习惯用 N 个 9 来表征系统可用性,比如 99.9%、99.999%。那分别对应的全年故障时间是:
- 1个9 故障时间 36.5 天
- 2个9 故障时间 3.65 天
- 3个9 故障时间 8.76 小时
- 4个9 故障时间 52.56 分钟
- 5个9 故障时间 5.256 分钟
- 6个9 故障时间 31.536 秒
- 7个9 故障时间 3.1536 秒
但是有的公司对可用性的定义是 pvlost/pv,请求失败的数量除以总请求数。比如晚上低峰服务宕机 10 分钟和高峰时期宕机 10 分钟是不一样的。这也是为什么要低峰上线。
6.2 高可用解决方案
6.2.1 异地多活
异地多活一般是指在不同城市建立独立的数据中心,没有主从的概念,每个机房都是独立平等的。如果某个机房发生故障,可以直接切流。原来的主从结构,存在单点故障的可能性,异地多活可以解决这个问题。
异地多活面临的主要挑战是网络延迟和数据一致性;机房间网络延时一般是 30 ms。一致性表现在用户在任何一个机房写入的数据,是否能在任何一个机房读取的时候返回的值是一致性的。通过重试、监控、回灌等方式保证数据低延迟和最终数据一致性,就可以考虑把系统改造成异地多活的形式。
6.2.2 限流和熔断
在流量异常时对系统的自我保护,对多余的流量直接拒绝,保证核心业务。比如用户服务,往往会提供给十几个需求方查询功能,如果对接入方的 QPS 没有限制,某个系统出现故障,QPS 增长了几十倍,可能就把服务拖垮了,整个集群都不能提供服务了,我们一般给不同的调用方设置不同的配额,比如 400 qps,超过这个数值就会拒绝,保证能给其他的系统提供正常的服务。
从限流的维度上可以分为单机限流和分布式限流。单机限流是每个实例上限制多少 QPS,单机限流的优点是不需要外部交互,性能和可靠性比分布式限流好,但也存在一个问题,不同的实例计算能力可能不同,但是每个实例上的代码是一样的,也就是实例限制的 QPS 是一样的。不过由于限流不是一个准确性很强的代码模块,实例之间的计算能力也不会相差很多,因此,单机限流在很多情况下是非常好的方式。分布式限流整个需求方的请求在 X 秒执行 Y 次,一般使用 Redis 计数。
6.2.3 隔离
为了节省机器资源,往往把不同的服务部署到一个物理集群上,或者把不同业务的表存在同一个数据库中。如果 A、B、C 服务混部,B 服务出现故障,把物理机的 CPU 占用完了,那么 A 服务和 C 服务也无法正常使用。如果独立部署可以避免这个问题,但是完全独立部署会浪费很多机器,因此在虚拟化的时候,要做到实例之间 CPU、磁盘等物理资源相互隔离。如果是非常非常核心服务,比如支付,集群独立部署保证稳定性,如果是一般的服务,使用虚拟化技术隔离即可。
6.2.4 解耦
使用微服务的架构,将系统拆分成独立的子服务。微服务之间相互解耦,能够减少系统的复杂度,提升稳定性。比如上面说的营销系统,就是由促销引擎、优惠券、配置化平台等多个微服务构成的。微服务之间通过 RPC 进行通信,内部逻辑是高内聚的。各个模块可以快速上线迭代,也可以独立部署,大大提高了研发效率和稳定性。
6.2.5 降级
当服务出现异常时,能自动降级,不至于处于完全不可用的状态。比如电商中的列表页和详情页会依赖商品服务,如果商品服务全挂了,可以自动切到静态页面,静态页面是每天晚上定时跑当前线上的页面信息存储下来。在极端情况下能够满足用户的浏览需求。降级一般是有损失的,比如这种情况不会展示商品的优惠信息,会减少用户的停留时长、购买等。
6.2.6 扩容
在大型活动比如双 11 来临之前,会对 QPS 增长的范围进行预估,提前把机器准备好,对各个服务进行扩容。各个微服务可以方便的扩机房、扩实例、扩存储容量,这需要依托公司内部强大的运维平台,运维平台能够管理机器、自动部署环境、部署代码、进行流量调配等。如果没有强大的运维平台,使用 Nginx 负载均衡,提前扩上机器,抵御流量来袭。
6.2.7 灰度发布
上线过程中按照预览机、单台、单边、全量的方式,如果有问题立即回滚,最大程度上降低损失。新功能上线需要评估效果时,可以抽取一部分的用户,AB 组对照试验,如果效果好,再推全。
6.2.8 监控召回
线上核心接口都应该加上监控,能够在上线过程中召回问题,及时回滚。监控也分为机器维度的监控,比如 CPU idle、磁盘 IO、网络 IO、磁盘剩余空间等;接口稳定性维度的监控,比如 http 状态码分布,接口异常错误码等;业务逻辑的监控,比如配置上测试商品和测试活动,每隔 10s 请求一下接口返回是否符合预期。监控要注意准确率和召回率,如果报警配置的不合理,会造成开发人员麻痹,不去及时处理问题。
6.2.9 全链路压测和定时演练
在流量低峰进行全链路压测,找出整个系统中的瓶颈,进行优化和扩容。比如在 O2O 电商系统中,都是分城市开通的服务,可以找一个未注册的城市,批量创建一批测试用户,配置压测商家、团单、压测活动,让这些账号模拟下单全流程,对全流程的各个服务进行压测,压测出整个服务的最大容量和系统瓶颈,针对有问题的服务,及时优化。
小结
本文聊了一下 O2O 电商中的几个重要模块和高可用系统搭建的通用方法,但是由于内容过多,不能面面俱到,只能作为一个引子,抛转引玉,引发出更多的探讨。